


北京时间 2026 年 7 月 1 日, Anthropic 宣布 Fable 5 解除封禁,并发布了新模型 Sonnet 5, Anthopic 宣称该版本显著提升了自主执行任务和调用工具的智能体 (Agent) 能力,性能逼近旗舰级 Opus 4.8,采用了全新的分词器。其定价为:
| 模型 | 输入(每百万 Token) | 输出(每百万 Token) | 备注 |
|---|---|---|---|
| Sonnet 5 | 3 美元 | 15 美元 | 8 月 31 日前优惠价 2 美元 / 10 美元 |
| Opus 4.8 | 5 美元 | 25 美元 | 无限时优惠 |
| Fable 5 | 10 美元 | 50 美元 | 7 月 7 日后订阅额度不再包含,需按 API 付费 |
无论输入还是输出,Sonnet 5 的单价都只有 Opus 的六成。但单价更低不代表实际更省——后面会提到,按实际任务成本衡量,Sonnet 5 完成同一任务反而可能花更多钱,这也是后面争议的根源。
Sonnet 5 相比 Opus 单价全面更低,又完成了一次大版本号的跃迁,你可能会有疑问,Sonnet 5 到底值得使用吗?
结论
这里直接上结论:
Sonnet 5 不适合直接作为默认模型使用,其性能不如 Opus 4.8,但是在写作方面获得了表现出色的评价。
因此对于大型、大规模代码编辑,直接使用 Opus 4.8 系列即可,如果预算充足则使用 Fable 5(7 月 7 日后 Claude Code Pro 订阅中将无法直接使用 Fable,需要按照 API 定价收费)。
当需要考虑费用成本、需要较新的知识库(已更新至 2026 年 1 月)时,以及在小型任务、写作任务中,可以切换为 Sonnet 5。
对于更简单的任务,使用其他更经济的模型即可覆盖。
Sonnet 5 是什么?
按照 Anthropic 官方新闻页的说法,Claude Sonnet 5 是 Sonnet 系列的新一代模型,定位是「面向编码、Agent 和专业工作的前沿性能模型」。Anthropic 将其放在 Sonnet 产品线上,而不是 Opus 或 Fable 这种更高阶、更昂贵的旗舰线,这本身就是一个信号:Sonnet 5 不是用来刷榜的模型,而是用来「天天用」的模型。
外媒报道也提到,Sonnet 5 被设计为一个更适合日常高频使用的模型,重点加强了浏览、编码、规划、知识工作和自主任务执行能力,并已同步面向 Claude Free、Pro、Max、Team、Enterprise 等所有订阅层级开放。这种「首发即全量」的铺开方式,也印证了它的定位:主力机型,不是尝鲜彩蛋。
简单说,Sonnet 5 不是「最高规格炫技模型」,而是 Anthropic 想推给大多数 Claude 用户的主力工作模型。
这和过去 Anthropic 对 Sonnet 系列的定位一致: 比 Haiku 强,比 Opus 便宜,适合作为日常主力。
社交媒体评价:完全不值
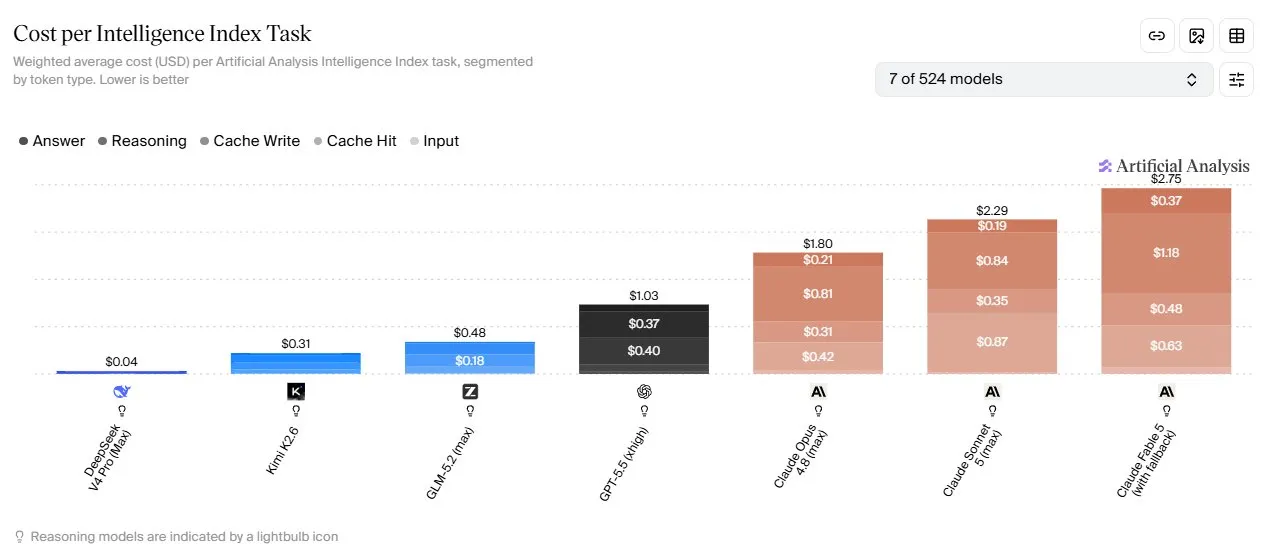
一张来自 Artificial Analysis 的「Cost per Intelligence Index Task」图表显示,Claude Sonnet 5 在 Max 思考等级 下的单任务成本明显高于 GPT-5.5、GLM-5.2、Kimi-K2.6、DeepSeek-V4-Pro 等模型,甚至高于 Opus 系列。于是有人直接总结:
Sonnet 5 直接扔进垃圾桶
比 Opus 4.8 Max 贵 1.2 倍
比 GPT-5.5-xhigh 贵 2 倍
比 GLM-5.2 贵 5 倍
比 Kimi-K2.6 贵 7 倍
比 DeepSeek-V4-Pro 贵 57 倍
对此 OpenClaw 的作者 Peter Steinberger 直接 评价: 每 Token 价格 != 实际任务成本 != 最终生产力成本。
由于 Sonnet 5 的智能没有实现很大进步,需要消耗更多的 Token 来完成任务,导致总消耗反而比 Opus 系列更多。
因此对于大型、大规模的代码编辑项目直接使用更高智能的 Opus 系列即可。
争议点:Sonnet 5 贵不贵?
贵。
尤其是放在 2026 年这个时间点看,Sonnet 5 的成本压力会比过去更明显。
Artificial Analysis 的成本图并不是单纯比较输入 / 输出 Token 单价,而是按 Intelligence Index 任务加权计算,包括 Input、Answer、Reasoning、Cache Write、Cache Hit 等不同 Token 类型。它试图回答的是:完成一个标准化智能任务,平均要花多少钱。
这就解释了为什么「看起来 API 单价差不多」的模型,实际任务成本可能完全不同。举个例子:如果一个模型平均需要 3 轮工具调用、每轮都要重新读一遍上下文才能完成任务,而另一个模型 1 轮就能给出可用结果,那么即使两者单价一致,前者的实际账单也会是后者的数倍——差距不是来自定价表,而是来自「模型解决问题需要绕多少路」。
一个模型如果:
- 输出更长
- 推理 Token 更多
- 工具调用链路更重
- 不擅长一次完成,需要反复修正
- Cache 利用率不高
那么它的实际成本就会被拉高。
这也是很多人吐槽 Sonnet 5 的原因:
Anthropic 的模型越来越像豪华燃油车,性能强,但开起来不便宜。
但只看单任务成本,也容易误判
问题在于,开发者真正关心的往往不是「跑一次 Benchmark 花多少钱」,而是:
它能不能少折腾我?
对写代码、重构项目、分析仓库、修 Bug、跑 Agent 来说,模型成本只是总成本的一部分。更重要的是:
- 第一次方案是否靠谱
- 是否理解大型项目上下文
- 是否会乱改无关文件
- 是否能保持长期任务稳定
- 是否能自己发现问题并修正
- 是否减少人工 review 和返工
如果 Sonnet 5 在这些方面明显强于便宜模型,那么它即使「每次任务更贵」,最终仍然可能更划算。
打个比方:假设一个中型重构任务,便宜模型单价是 Sonnet 5 的五分之一,但因为理解不了项目边界,需要反复试错 6 轮才能勉强跑通,且中途还改坏了两个无关文件,需要你手动回滚;而 Sonnet 5 单价更高,但 2 轮就能给出可用方案,且不会牵连其他文件。算上你自己排查、回滚、二次确认的时间成本,便宜模型的「总成本」未必比 Sonnet 5 低——只是这部分成本没有出现在账单上,而是变成了你的时间。
这就像云服务器:
便宜的很便宜,但如果一天炸三次、IO 抽风、网络绕路,最后浪费的是人的时间。
AI 模型也是一样。
Sonnet 5 真正的价值:Agent 和代码工作流
从 Anthropic 的宣传重点看,Sonnet 5 最核心的卖点不是普通聊天,而是 Agentic Workflows。
也就是让模型不只是回答问题,而是能连续执行任务:
- 阅读项目文件
- 理解现有架构
- 制定修改计划
- 调用终端
- 修改代码
- 跑测试
- 根据报错继续修
- 最后总结变更
这正是 Claude Code、Cursor、Windsurf、OpenClaw 这类工具最依赖的能力。
对这类场景来说,模型的「听话程度」「上下文稳定性」「工具调用判断」往往比单纯的知识问答更重要。Anthropic 过去几代 Sonnet 在代码 Agent 场景中口碑一直不错,Sonnet 5 如果继续强化这条路线,那它仍然会是开发者绕不开的模型。
尤其是复杂项目里,很多模型不是不会写代码,而是:
- 看不懂项目边界
- 喜欢重写整个文件
- 改 A 坏 B
- 测试失败后开始胡猜
- 上下文一长就开始失忆
- 看到报错只会重复同一个错误修法
如果 Sonnet 5 能减少这些问题,那么它就不是单纯的「贵」,而是「贵但省心」。
那它适合所有人吗?
不适合。
如果你的需求只是:
- 翻译
- 摘要
- 写普通文章
- 生成短代码片段
- 问一些常识问题
- 做轻量客服 QA
- 批量处理低价值文本
那 Sonnet 5 很可能不是性价比最高的选择。
这类任务已经进入「模型过剩」阶段。GLM、Kimi、DeepSeek、GPT 的中低价模型都能做得不错。尤其是批量任务,成本差距会被无限放大。
比如一篇博客摘要、一个 JSON 转换、一个普通 SQL 生成任务,Sonnet 5 的优势可能并不能抵消它的成本。
这时候更合理的策略是:
便宜模型跑基础任务,Opus / Fable 系列处理大型复杂的任务,当有成本考虑是,将一些中阶的小规模任务交给 Sonnet 5 处理。
我的建议:不要把 Sonnet 5 当默认模型无脑用
Sonnet 5 最适合的使用方式,不是「所有请求都丢给它」,而是把它当成一个经济型的工作模型。
可以这样分层:
1. 普通文本任务:不用 Sonnet 5
翻译、润色、改标题、写摘要、生成普通 Markdown,用便宜模型就够了。
这些任务对推理深度、工具调用、项目理解要求不高,用 Sonnet 5 属于杀鸡用牛刀。
2. 一般代码片段:看情况
写一个简单函数、改一个 CSS、生成一个 Docker Compose,便宜模型也能胜任。
但如果它开始反复出错,或者你已经花了 10 分钟纠错,那就应该可以尝试切换 Sonnet 5。
便宜模型最贵的地方,是让你以为它快好了。
3. 中小型代码任务:可以用 Sonnet 5
例如:
- 修改单个页面
- 补一个组件
- 写一个脚本
- 修一个明确报错
- 添加一个简单 API
- 生成测试用例
- 对已有代码做小范围重构
这类任务的特点是边界清晰、上下文较短、失败成本较低。Sonnet 5 在这里可以发挥 Claude 系列一贯的代码理解和指令遵循能力,同时比 Opus 4.8 单价更低。
如果任务本身不复杂,用 Opus 4.8 反而有些浪费;但如果用更便宜的模型反复出错,Sonnet 5 就是一个不错的折中选择。
它适合处理「需要一点智能,但还不值得动用最高智能模型」的代码任务。
4. 大型项目的开发与重构:直接使用更高智能的模型
如果你的目标不是修一个小 Bug、改一个组件、写一段脚本,而是让 AI 参与实现一个完整项目,那么 Sonnet 5 反而不一定是最优选择。
这类任务通常包括:
- 从零搭建一个完整应用
- 设计项目架构
- 实现多模块功能
- 连续修改几十个文件
- 处理数据库、鉴权、状态管理、路由、部署配置
- 长时间运行 Claude Code / Codex / OpenClaw 这类 Agent 工具
在这种场景里,模型最重要的不是「单价低」,而是「一次做对的概率高」。
大型项目的成本并不只是 Token 成本,而是由多部分组成:
- 模型理解需求的成本
- 模型维护上下文的成本
- 多轮修改产生的返工成本
- 改错文件带来的回滚成本
- 测试失败后的排查成本
- 人工 review 和补救的时间成本
如果一个模型智能略低,它可能每一步看起来都能做,但组合起来就会出现问题:前面设计的架构后面忘了,刚写好的接口下一轮又被改坏,A 页面修好了 B 页面挂了,最后整个项目进入「能跑但不敢碰」的状态。
这也是为什么在大型项目里,应该优先使用 Opus 4.8、Fable 5 这类更高智能模型。
它们的单价更高,但在复杂任务中更容易保持全局一致性,能减少无效尝试和重复修复。尤其是当任务涉及架构设计、跨文件重构、测试修复和长期上下文时,更高智能模型带来的稳定性往往比价格差异更重要。
Sonnet 5 更适合做局部任务:
比如写一个页面、改一个模块、生成一段文案、补一个测试、修一个明确的报错。
但如果你要让 AI 从头到尾实现一个大型项目,尤其是需要连续运行 Agent 多小时,那么更合理的策略是:
直接使用 Opus 4.8 或 Fable 5,不要为了省一点单价把项目交给 Sonnet 5 硬跑。
因为大型项目里最贵的不是模型,而是模型犯错之后你还要继续相信它。
Sonnet 5 的问题:Anthropic 还是那个 Anthropic
Sonnet 5 的发布,也再次暴露了 Anthropic 的老问题:
模型很好,但生态和价格让人焦虑。
Claude 的体验一直很强,尤其是代码和长上下文任务。但 Anthropic 在可用性、额度、区域、订阅限制、API 成本和第三方工具支持上,始终不像 OpenAI 那样稳定。
更重要的是,随着 AI Agent 消耗越来越大,「订阅制无限用」这件事本身就越来越难持续。此前已有分析指出,重度 AI 用户实际消耗的 API 等价成本可能远超订阅价格——一个长期跑 Agent 任务的开发者,一天消耗的 Token 换算成 API 价格可能就超过月费本身。这意味着 AI 公司未来很可能继续向更细粒度、更接近成本的计费方式调整,比如更严格的用量上限、分层限速,或者像 Sonnet 5 这样在输出端悄悄提价。
所以 Sonnet 5 的问题不是单个模型贵,而是代表了一种趋势:
好模型会越来越强,但真正便宜随便用的时代正在结束。
一句话总结
Sonnet 5 不是便宜模型,也不是最强模型,而是一个适合写作和中小型任务的 Claude 日常模型。 它在代码编辑领域没有找到一个足够舒服的位置:便宜任务轮不到它,复杂任务又不如直接上 Opus / Fable。
如果你把它当成 Opus 的廉价替代品,可能会失望;
如果你把它当成一个更适合日常文本和轻量工作的 Sonnet,它依然值得放进工具箱。


评论